




デイトラPythonコース徹底レビュー【自動化& 予測ツールを開発できる!】

こんにちは、web系フリーランスとして5年ほど活動しておりますしょーごです。
今回はデイトラ「Pythonコース![]() 」に挑戦しましたので、徹底レビューしていこうと思います。
」に挑戦しましたので、徹底レビューしていこうと思います。
デイトラPythonコースで学べること、何ができるようになるか、何を作るのか、自分には買いなのか、すべて

\無料動画が複数あり!/

この記事を書いたのは
しょーご(@samurabrass)
このブログ「しょーごログ」の運営者。本業でエンジニアとしてサイト制作やシステム開発を数年行っており、ブログとYouTubeで情報発信を行っている。駆け出しエンジニアのコーディング課題添削も行う

- YouTube分析アプリ、株価予測アプリなどを実際に開発
- 実務で使いたいアプリについてプロに相談可能
- カリキュラムはずっと見放題、講師へ一年間質問可能
- 数学不要でも取り組めるカリキュラム
- カリキュラム以外の開発に関する質問もOK!
\Pythonを本気で仕事にしたいあなたへ/

| コース名 |  Web制作コース |  Web制作アドバンスコース |  Webアプリ開発コース |  Webデザインコース |  ShopifyEC構築コース |  動画編集コース |  Webマーケティングコース |
| 学習内容 | Webサイトの構築 | Web制作の一歩上の フロントエンド技術 | Rails,Reactでアプリ開発 | Webやアプリデザイン | Shopifyサイトの構築と 運用 | YouTubeや ショート動画編集 | 広告やSEO LINEやレポーティング |
| 料金 | ¥129,800 | ¥79,800 | ¥129,800 | ¥129,800 | ¥99,800 | ¥99,800 | ¥109,800 |
| 卒業後の進路例 | Web制作会社に就職 フリーランスコーダー | コーダーからキャリアアップ フロントエンドエンジニア | Railsエンジニアとして 企業に就職 | フリーランスデザイナー デザイン会社に就職 | EC構築フリーランス Shopifyエキスパートの会社に就職 | YouTube,TikTokeの編集者 企業の動画広報担当 映像編集会社へ就職 | フリーランスで広告運用 マーケターとして就職 |
| 解説記事リンク | Web制作コースの評判・内容 | Web制作アドバンスコースの評判・内容 | Webアプリ開発コースの評判・内容 | Webデザインコースの評判・内容 | Shopifyコースの評判・内容 | 動画編集コースの評判・内容 | Webマーケコースの評判・内容 |
| 公式サイト | Web制作コース | Web制作アドバンスコース | Webアプリ開発コース | Webデザインコース | ShopifyEC構築コース | Webマーケティングコース |
- デイトラPythonコースとは?
- デイトラPythonの無料体験する方法
- デイトラPythonコース初級編
- Pythonでプログラミングする準備をしよう
- SEOで狙える大手企業がいないキーワードを自動で収集+結果を書き出そう
- 狙うキーワードの競合サイトのタイトル、見出しを分析してSEO上位を狙おう
- ページの内部リンクを可視化して、内部SEOを強化しよう
- Twitterの色々なデータを分析してフォロワーを増やそう
- DAY22 PythonからTwitterを操作しよう
- DAY23 Twitter APIを取得しよう
- DAY24 Twitter APIを使って特定のキーワードで期間を指定してつぶやきを取得してみよう①
- DAY25 Twitter APIを使って特定のキーワードで期間を指定してつぶやきを取得してみよう②
- DAY26 Twitter APIを使って特定キーワードで期間を指定してつぶやきを取得してみよう③
- DAY27 ツイートを感情分析してみよう①
- DAY28 ツイートを感情分析してみよう②
- DAY29 機械学習を用いていいねの伸びやキーワードの伸びを予測してみよう①
- DAY30 機械学習を用いていいねの伸びやキーワードの伸びを予測してみよう②
- Pythonコース中級編編
- 株価を予測してみよう
- GithubとのTwitterとの言語人気を比較して、トレンド言語を探そう
- 特定のキーワードで直近で10万回以上再生されバズっている動画をリストアップしよう
- 形態素解析を使ってバズってる動画によく使われている決め台詞(ネガポジ分析)
- 特定のキーワードで24時間以内に数万回再生されている動画が出たらLINEに通知しよう
- 自分の動画がライバルの関連動画にどれぐらい露出され順位はどのくらいか調べよう
- 機械学習を使って世界規模の株価予測コンペで賞金をゲットしよう
- ここまで読んでくれたあなたへ
- デイトラ申し込みから学習開始までの流れ
デイトラPythonコースとは?

Pythonコースは、Excelシートにまとめる作業の自動化や、Webからの情報収集の自動化、マーケティング分析、業務の効率化や高度な分析ツールなどの開発スキルを学習できるコースです。
| 学習言語 | Python、Django |
| 受講場所 | 完全オンライン |
| 期間 | 3ヶ月(カリキュラム閲覧はずっと可能、メンターサポートは1年間) |
| 講師 | ・現役フリーランスエンジニア |
| 主なサポート | ・毎日13時〜23時のチャットサポート ・不定期でウェビナー開催 ・不定期でのオフライン勉強会 |
| 料金 | ¥89,800 |
| 転職保証 | なし |

デイトラ「Pythonコース![]() 」を一言でいうと、
」を一言でいうと、
勉強しながら日常生活にも役立つプログラムを作ることに特化したコース
と言えます。
\業界最安のPythonスクール/
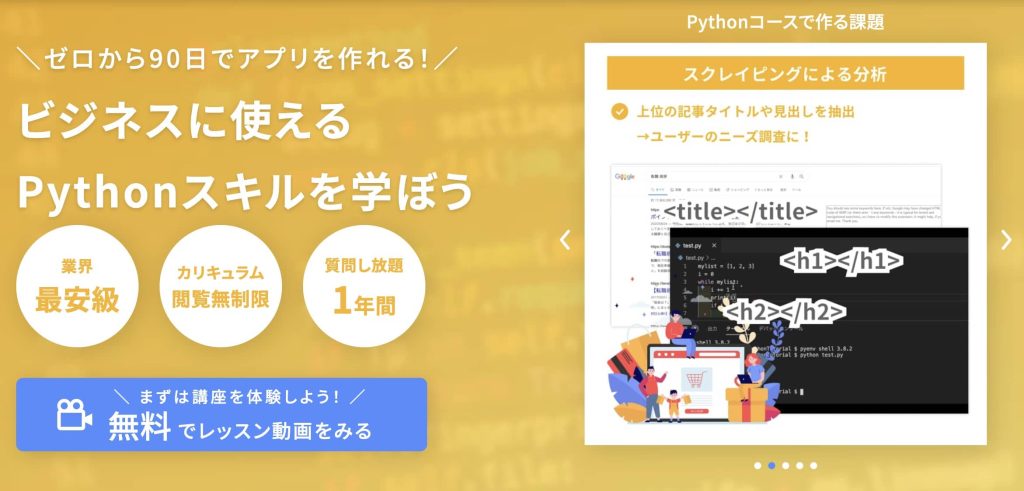
デイトラPythonコースで作るもの
では具体的にどんなものを作るか列挙してみました。
- Pythonで特によく使う文法
- 業務自動化ができるブラウザの自動化
- 人気のツイートが一目で分かるTwitterのデータ分析
- 未来の株価を知れる予測
- Youtubeの登録者をコスパ良く伸ばすためのデータ分析
- 投資コンペで機械学習を用いた株価予測
- Tinderの自動化による恋人探し
- LINEチャットボット制作
- Instagramのフォロワーを伸ばすためのインサイト分析
- Djangoを使用したSNS分析アプリ作成
- 写真から年齢を判定するLINE診断botを作ろう
- LINEで雑談チャットボットを作ろう
- DjangoでTwitter / Instagram / YouTubeの自動化コードをアプリ化しよう
なんかわからないけどめちゃくちゃワクワクしませんか笑?
ここがデイトラ「Pythonコース」が他スクールを凌駕する点です。
上級編コースで作るもの例


デイトラPythonコースのメンター

デイトラ「Pythonコース」はカリキュラム作成とメンターにお二人のエンジニアが参画されています。
お二方ともかなり経験豊富なエンジニアで、まにゃpyさんはもともとマーケティングをしており、その自動化でPythonにのめり込んだ方で、様々なPython最新情報を発信されている方です。
はる@プログラミング講師さんはスーパーフルスタックエンジニアで海外で活動されてたりもしている方です。
デイトラPythonコースの料金

デイトラ「Pythonコース」の料金は¥89,800です。
通常プログラミングスクールのPythonコースは20~30万円であることが多い中、10万円を切るのは嬉しいですね!

デイトラPythonの無料体験する方法
まずはデイトラ![]() から「無料で講座を体験する」のボタンを押してください。
から「無料で講座を体験する」のボタンを押してください。

その後、デイトラ![]() に登録してください(お金はコースを購入しない限り、かかりません)
に登録してください(お金はコースを購入しない限り、かかりません)

その後、管理画面に入ったら、下の方の「コース一覧」から気になるコースを選べば、複数の無料講義動画を閲覧することが可能です!

\無料動画が複数あり!/
デイトラPythonコース初級編

- 基礎文法
- ブラウザ自動操作→キーワード自動収集
- 狙うキーワードの競合サイトのタイトル、見出しをPythonに自動で抽出させ、スプレッドシートに書き出す
- ページの内部リンクを可視化して、内部SEOを強化
- Twitterの色々なデータを分析してフォロワーを増やそう
- 時系列予測して伸びるキーワードを分析
Pythonでプログラミングする準備をしよう
DAY01 はじめに
環境構築と基礎文法を学びました。
- python環境の構築
- fotmatメソッド、f-string
- stripメソッドとlen関数、replaceメソッド
- 辞書、リスト、タプル
こういった基礎文法は「退屈だなぁ」と思うかもですが、実際にPythonでめちゃくちゃ使うもののみを集積していますので、
ここで理解を固めておきます。
DAY02 条件分岐や繰り返し、モジュールのインストールについて学ぼう
- 条件分岐と繰り返し(for,while,if文、elif文、else文)
- 例外の処理(try except文)
- 組み込み関数、モジュール、import
引き続きPythonの基礎を学んでいきます。
特にモジュール、パッケージ、ライブラリについてはこのコースで多用していきますので、しっかり理解していきます。
・モジュール
.pyファイル
・パッケージ
モジュール詰め合わせフォルダ
・ライブラリ
モジュールやパッケージ詰め合わせ群
外部ライブラリをターミナルでインストール(pip install)し、VSCodeでモジュールをimportして機能を使えるようにします。
DAY03 関数について学ぼう
同じ処理は何度も出るようであれば、関数化するのが一般的です。
HTML,CSSなどにおいても何回も同じ処理が出てくるようなら同じclass名に揃えるかと思いますが、同じようなことです。
DAY04 エラーが起こった時の対処法を知ろう
プログラミングをしていると、エラー文と頻繁に遭遇することになります。DAY04にして自分は既に以下のようなエラー文を見ています。
- SyntaxError(文法)
- IndentationError(インデント)
- TypeError(型)
このパートでは主要なエラー文を予習しておきます。プログラマーにとってエラー文はヒントを教えてくれる友達なので、意味をしっかり理解しておきましょう。
\業界最安のPythonスクール/
SEOで狙える大手企業がいないキーワードを自動で収集+結果を書き出そう
DAY05 Pythonによるブラウザ自動操作①
- seleniumでGoogleのトップページを開く
- seleniumを使ってGoogleから特定キーワードで検索する
seleniumというライブラリでブラウザを自動操作していきます。
作成したpythonコードを実行したら、Chromeブラウザが自動で立ち上がり、キーワードが入力されて検索が行われたのでシンプルにすごいと思いましたw
DAY06 Pythonによるブラウザ自動操作②
- 検索結果の1位から10位までのURLを取得
- プログラムの全体像の解説、with構文を使用したテキストファイルの読み込み
「検索結果の1位から10位までのURLを取得」と聞くと聞こえは難しそうですが、Chromeブラウザはseleniumで簡単にアクセスできるので、
結果の取得をDAY04までに習った基礎文法を用いながら書いていきます。
ほんの少しだけコードをお見せします。
# '検索キーワードリスト.txt'ファイルを読み込み、リストにする
with open('検索キーワードリスト.txt') as f:
keywords = [s.rstrip() for s in f.readlines()]DAY07 Pythonによるブラウザ自動操作③
- 正規表現の基礎、正規表現チェッカーの使い方
- 正規表現の最長一致と最短一致
文章から文字列やテキストを取り出す時にとっても便利な正規表現を学びます。
/^d{3}-d{4}$/DAY08 Pythonによるブラウザ自動操作④
pythonは標準で「re」という正規表現用モジュールを含んでいるので、reモジュールを使用していきます。
text = "りんごをひとつ、みかんをふたつ、パイナップルをみっつ食べました"
m = re.search("(ひとつ|ふたつ|みっつ)", text)
print(m.group())
# この場合一番最初に一致した「ひとつ」が返されるこのreモジュールを使い、予め読み込んでおいた企業ドメインを正規表現で判断して、その企業ドメインが含まれている場合は除外するというものです。
今回やりたいこととして、SEOで狙える大手企業がいないキーワードを自動で収集+結果を書き出そう
というものなので、リストアップしておいた企業ドメインの記事は正規表現で除外する必要があるということです。
DAY09 プログラムを関数化してみよう
コードを関数化するなどしたら、いよいよ実行していきます。
以下のTweetがわかりやすいかなと思います。
大手がいないキーワードを一覧にまとめてくれるので、非常にありがたい限り。
少し時間がかかるので、Pythonがキーワード抽出を行っている間はお昼を食べていました
狙うキーワードの競合サイトのタイトル、見出しを分析してSEO上位を狙おう
複数のキーワードで検索して、それぞれのキーワードのグーグル検索の見出しの1位から10位までのタイトルと説明文、URL、見出し(H1タグ~H5タグ)を取得するプログラム
上位サイトの「タイトル」や「見出し」、を見ることによってそのキーワードで記事を書く際に満たすべきトピック(話題)を網羅的に把握することができる。
そして、その分析したトピック+αの記事を書くことでユーザーに刺さる記事を書くことができ、上位表示によりつなげやすい記事を書くことが可能となる。
つまり、このプログラムを使えば「あるキーワード」で記事を書く際に必要なトピックを一覧でパッと把握することができるようになり、記事調査の時間を時短することができる。

DAY10 Googleスプレッドシートの準備
まずは使う外部ライブラリをインストールしていきます。
- requests
- BeautifulSoup
- gspread
- oauth2client
またAPIについても学んでいきます。
APIはPythonではデータ収集する際によく使用するので、どのようなものなのか、どのように使うのかを動画を見てしっかり理解します。
ここではスプレッドシートのAPIキーを取得しました。
DAY11 Pythonによるブラウザ自動操作
スプレッドシートを操作するための準備をしていきます。
引き続きseleniumを使ったブラウザ自動操作のコードを書いていきます。
- 検索ボックスをHTMLから取得
- 検索ボックスにキーワードリストから取得したキーワードを一つずつ入力
- 検索実行
この流れがだいぶ理解できるようになってきました。
DAY12 条件分岐と繰り返しを使って要素を取り出してみよう
検索結果からtitle.url.descriptionなどを取得するために、検証ツールで要素を調べていきます。

ここの値を検索結果から取得して、用意しておいた空の辞書(オブジェクトのようなもの)に入れてあげます↓
items = {
'keyword': keyword,
'title': ['タイトル'],
'url': [],
'description': ['説明文'],
'h1': [],
'h2': [],
'h3': [],
'h4': [],
'h5': []
}DAY13 スクレイピングをしてみよう
requests
HTTP通信用のPythonライブラリであり、HTMLを取得する際にとても役立ちます。
BeautifulSoup
requestsで取得したHTMLを解析して情報を取り出す際にとても役立ちます。
スクレイピングを行う際は、この2つのライブラリをセットで使うことが多いので覚えておきます。
ここでは「記事中のh1~h5タグを自動取得する」コードを書いていきます。
DAY14 Googleスプレッドシートに結果を書き込んでみよう①
ここではスプレッドシートに結果を書き込むための準備を行います。
- 準備しておいた認証情報でPythonでログイン処理
- 作っておいたワークブックを参照
- ワークシートを作成
これらを全部Pythonで行います。ほとんどお決まりの処理なので、覚える必要はないです。
DAY15 Googleスプレッドシートに結果を書き込んでみよう②

最終的にこのようなリストを作成いなければならないので、
- 順位
- タイトル
- URL
- 説明文
- H1~H5タグ
をシートに挿入していく処理を書いていきます。
コードを一部だけチラ見せするとこんな感じです。
try:
# 共有設定したスプレッドシートのシート1を開く
workbook = gc.open_by_key(SPREADSHEET_KEY)
# ワークシートを作成(タイトルがkeywordで、50行、50列)
worksheet = workbook.add_worksheet(title=items['keyword'], row='50', cols='50')
# シートが作成されたらフラグを立てる
flag = True
# スプレッドシート書き込み処理
# キーワードの書き込み
worksheet.update_cell(1, 1, '検索キーワード')
worksheet.update_cell(1, 2, items['keyword'])
# 1秒待機
time.sleep(1)
# 順位の書き込み
column = 2
worksheet.update_cell(2, 1, '順位')
for ranking in range(1, 11):
worksheet.update_cell(2, column, ranking)
column += 1
# 3秒待機
time.sleep(3)
# 「タイトル」の書き込み
column = 1
for title in items['title']:
worksheet.update_cell(3, column, title)
column += 1
# 3秒待機
time.sleep(3)DAY16 プログラムを関数化してみよう
今回の処理の流れと関数化のメリットをわかりやすく伝えるために、講義動画のスクショを使わせていただこうと思います。
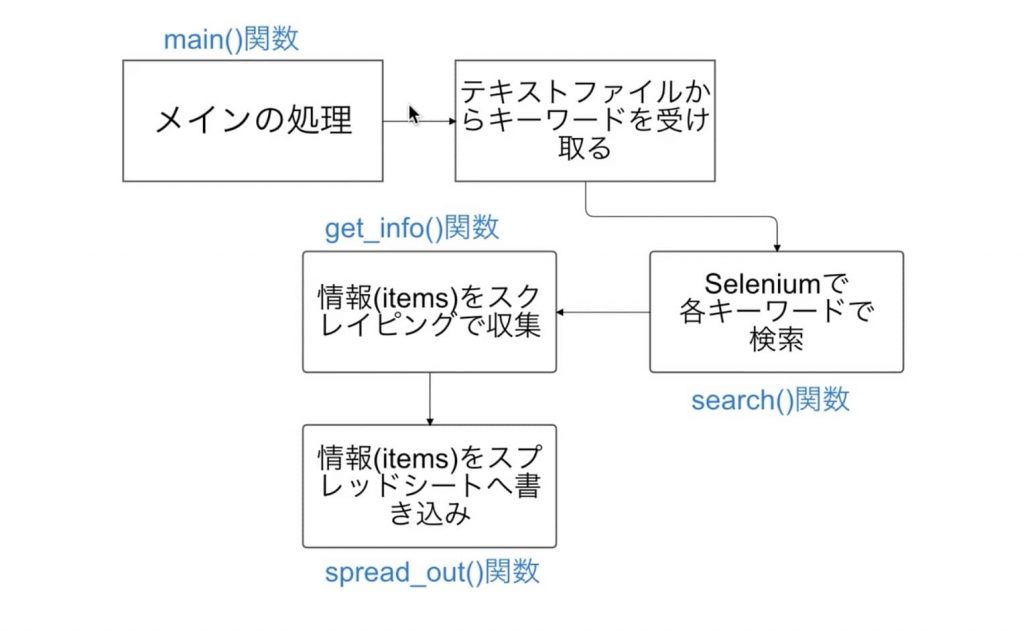
これまで処理を細切れに書いてきましたが、このように処理の塊ごとに関数化することによって、処理が置いやすくなったり、可読性保守性がよくなったりします。
狙うキーワードの競合サイトのタイトル、見出し(h1~h5)をPythonに自動で抽出させ、スプレッドシートに書き出す処理完成!
下は「JavaScript 勉強方法」のキーワードを用意してPyhtonに情報を持ってきてもらってスプレットシートにかき出した結果です↓
ページの内部リンクを可視化して、内部SEOを強化しよう

ホームページの内部リンクを可視化するツール
内部リンクの数とどんなページに内部リンクを送っているのかを可視化することで、内部SEO強化につながる

DAY17 Pythonでページの内部リンクを取得してみよう①
- urllib
- networkx
- matplotlib
ここでは今回分析するwebサイトページのURLなどを正規表現で取得するコードを書いていきます。
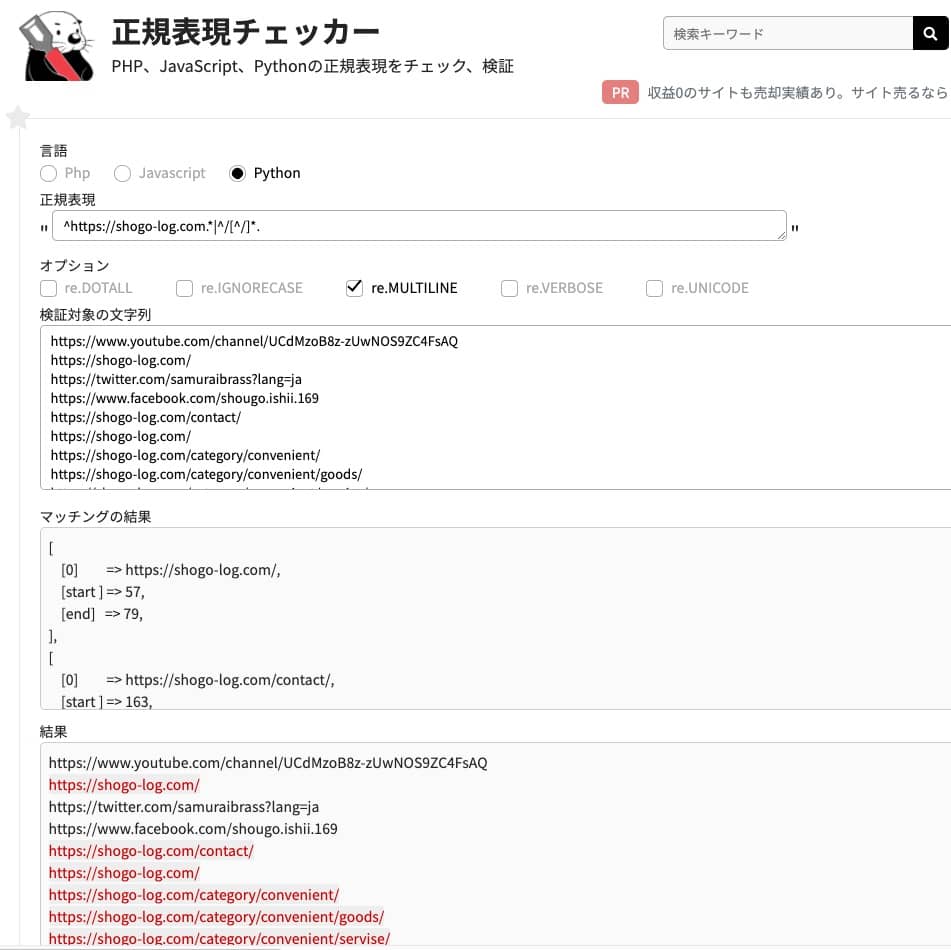
DAY18 Pythonでページの内部リンクを取得してみよう②
内部リンクを正規表現で取り出していきます。
正規表現チェッカーを使うとわかりやすいですね。
DAY19 Pythonでネットワーク図を書いてみよう
ネットワーク図の仕様を学んで、networkxモジュールを使って図を描画していきます。
- グラフオブジェクトの作成
- 頂点と辺や経路の追加
- レイアウトの指定
- ネットワーク図描画

この段階で汚いですが、ネットワーク図を描画することができました。

DAY20 ネットワーク図を見やすく整えていこう
さきほどのネットワーク図のスタイルを整えたり、関連性の高い内部リンクのみに絞って表示する処理を書いていきます。
- 正規表現でhttps://shogo-log.comの部分削除(かぶるため)
- feedやprofile,aboutなど内部リンクと関係性低いリンクを削除
DAY21 エラーを素早く解決するために、デバッグについて学び、プログラムを関数化してみよう
まずはデバッグについて学びます。
- ブレークポイントを置く
- 一行一行実行していく
- 変数などの中身を見る
デバッグはPythonに限らずプログラミング、web制作をするなら避けては通れない作業です。

デバッグがわかれば、ググって仮に答えが見つからなくても「どこでバグが起こっているかわかる」という面で、自己解決力が高くなります。


Twitterの色々なデータを分析してフォロワーを増やそう
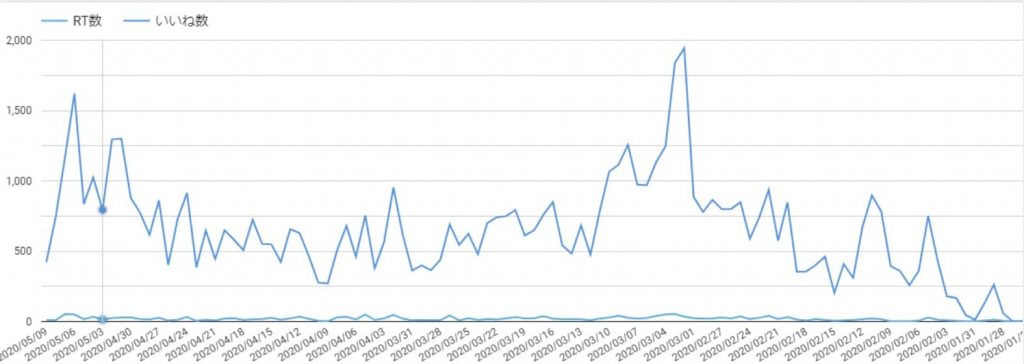
- Twitter APIを使って特定キーワードで期間を指定してつぶやきを取得
- ツイートを感情分析してみよう
- 機械学習を用いていいねの伸びやキーワードの伸びを予測してみよう
サービスの需要を調べることが可能になります。
サービスの需要を調べることができれば、Twitterでどのようなサービスが受けるのか?また、サービスを伸ばすためにはどのようなつぶやきをしていけばいいのか分かるようになります。
DAY22 PythonからTwitterを操作しよう
Twitter APIを取得する前にWeb APIとはどのようなものか学んでいきます。
DAY23 Twitter APIを取得しよう
個人的に割と鬼門でした笑
TwitterAPIは審査が厳格な上に、利用する理由やデータをどのように使うかなどを数百語の英語で送り、その後審査を通過しなければなりません。
私はDeepL翻訳で乗り切りました笑

自分の場合は送信してから30秒以内に返信があり、すぐにAPIキーを取得することができたので、
文字数以上をきちんと入力すれば自動的に許可が降りるのではと思いました。
DAY24 Twitter APIを使って特定のキーワードで期間を指定してつぶやきを取得してみよう①
- pandas(データを表にしてまとめてくれる)
- tweepy(Twitter APIの取り回しを簡単にしてくれる)
ここでは試しに、「デイトラ」のキーワードで「直近一週間でリツイートといいねが合計10以上のツイート」を集計してみます。

DAY25 Twitter APIを使って特定のキーワードで期間を指定してつぶやきを取得してみよう②
DataFrameというもの(表)を作成していきます。

- ユーザー名
- ユーザーID
- RT数
- いいね数
- 日時
- 本文
これらをDataFrameに整えていきます。
df = pd.DataFrame({'ユーザー名': list_username,
'ユーザーID': list_userid,
'RT数': list_rtcount,
'いいね数': list_favorite,
'日時': list_date,
'本文': list_text
})DAY26 Twitter APIを使って特定キーワードで期間を指定してつぶやきを取得してみよう③
pandasのメソッドで、作成したデータをCSVに出力してあげて完成です。デイトラのキーワードで検索をかけてみました。

DAY27 ツイートを感情分析してみよう①
Pythonによるネガポジ分析の方法
ツイートを感情分析するとは、つまるところネガポジ分析となります。
ネガポジ分析とは、ある文章や単語がネガティブかポジティブかその度合いを数値で調べる
という意味です。
どの単語がネガティブでどの単語がポジティブかは「極性辞書」というものに記載されているため、自分で用意する必要はありません。

janome(形態素解析をする)
DAY28 ツイートを感情分析してみよう②
最終的にこのようなものができました。
また、ここで取得できたツイートは自動でcsvにしてくれます。

DAY29 機械学習を用いていいねの伸びやキーワードの伸びを予測してみよう①
- pystan
- prophet
- plotly
ここでVSCodeではなく、「Jupyter Lab」という実行環境でコードを書いていくことになります。

ここで、pandasのメソッドでDataFrameを自由に操作できるように練習しておきます。

DAY30 機械学習を用いていいねの伸びやキーワードの伸びを予測してみよう②
初級編最終日は、Prophetを利用して実際にNocodeというキーワードの伸びを予測していきます。
- データを集める
- データの整形(規定のDataFrame)
- 機械学習の手法の選択(今回はProphet)
- データを学習させてモデルを作る(fit、make_future_dataframeメソッド)
- 出来上がったモデルを使って予測(predictメソッド)
Prophetで予測できるようにDataFrameを整形していき

機会学習自体は秒で終わりました笑
最終的にグラフに描画します。
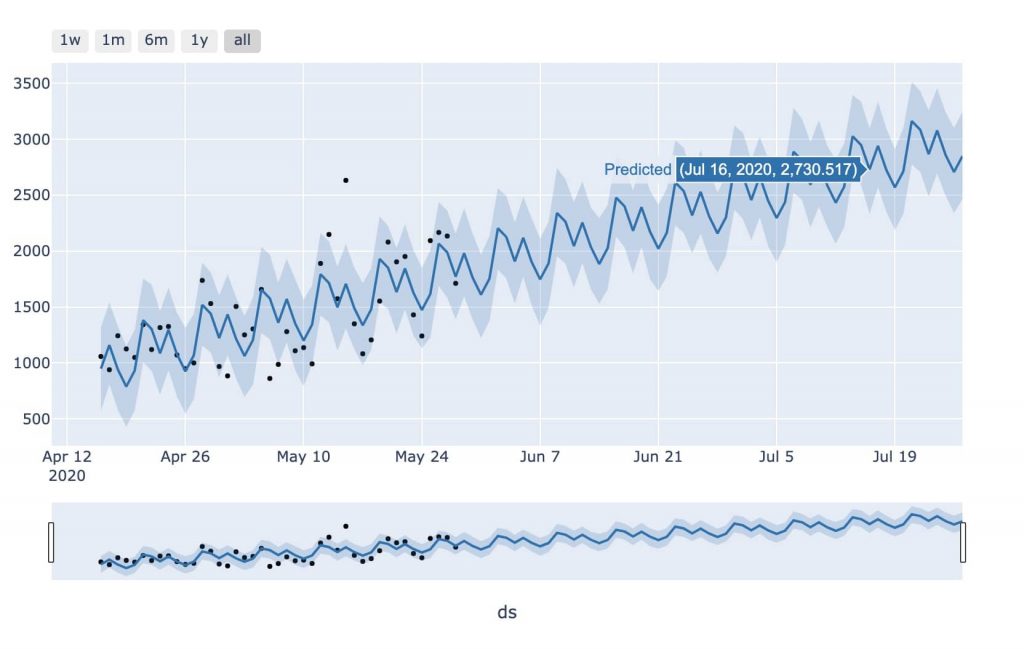

ちなみに「YouTube登録者数」「Twitterフォロワー数」も独自に時系列予測してみました。

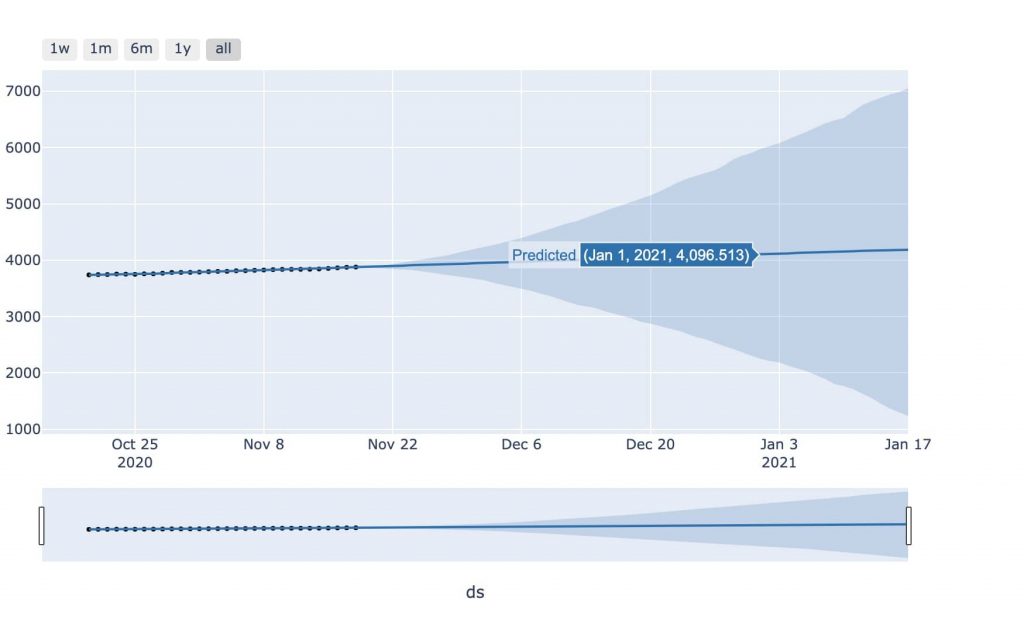
自分でCSVを用意できればなんでも測れます!!

Pythonコース中級編編

- 株価を予測してみよう
- GithubとのTwitterとの言語人気を比較して、トレンド言語を探そう
- 特定のキーワードで直近で10万回以上再生されバズっている動画をリストアップしよう
- 形態素解析を使ってバズってる動画によく使われている決め台詞(ネガポジ分析)
- 特定のキーワードで24時間以内に数万回再生されている動画が出たらLINEに通知しよう
- 自分の動画がライバルの関連動画にどれぐらい露出され順位はどのくらいか調べよう
- 機械学習を使って世界規模の株価予測コンペで賞金をゲットしよう
株価を予測してみよう
DAY31 <未来の株価を予測してみよう>株価のデータを取得しよう①
ソニーの株価を予測するために、これまで使ったseleniumとProphetを使っていきます。
株価の予測には「株価CSVデータ」が必要ですが、このCSVダウンロードからPythonで自動で行っていきます。
DAY32 <未来の株価を予想してみよう>個別株価の予測②
- まずは2013年から2020年までの株価CSVを取得する
- その後取得したCSV(DataFrame)を縦に結合し、一つのCSVとして出力
これにて検証用のデータが揃いました。

DAY33 <未来の株価を予測してみよう>個別株価の予測②
ここまででデータの準備はできたので、あとはProphetで時系列予測していきます。
ソニーの今後3年の株価予測をしてみました。

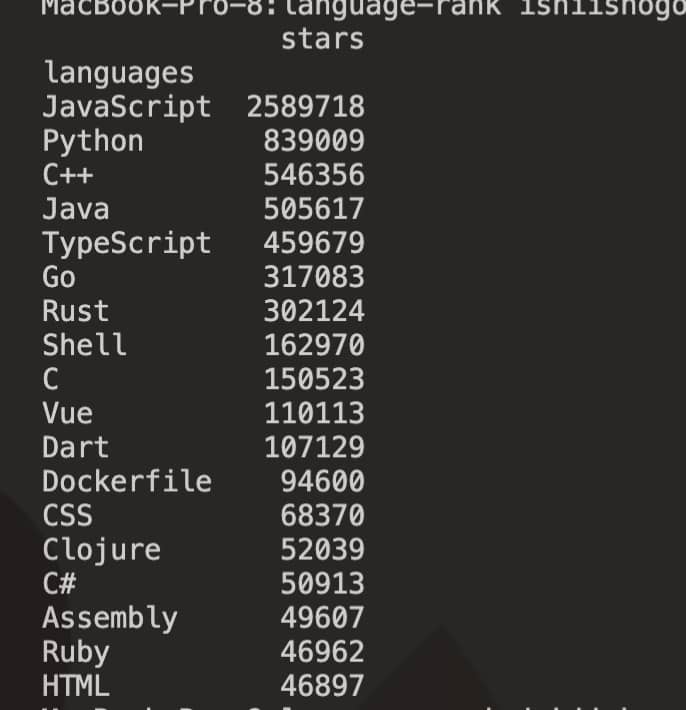
GithubとのTwitterとの言語人気を比較して、トレンド言語を探そう
DAY34 Githubからデータを収集しよう①
- Github APIを使ってスター数の多いリポジトリを集計
- 人気リポジトリの言語を判別し、データフレーム化
- データをスター数の多い順に並べ替え
Githubからアクセストークンを取得してアクセスしてデータをもってこれるようにしておきます。


DAY35 Githubからデータを収集しよう②
言語のいいね数ランキングは以下のようになりました。
DAY36 <課題>Twitterrから言語ごとのデータ収集をしよう
ここでPythonコース初めての課題です。
Twitter APIを使用して、過去7日間のプログラミング言語のいいね数のデータを取得
与えられるヒントは以下のようなものです。
- TwitterAPI情報のセット
- for文を使って言語ごとにTwitterデータを取得していく
tweepy.Cursorメソッドを使う - ツイートのデータdataから言語ごとのデータフレームdfを作成
辞書の形またはリストの入れ子の形で作成 - 言語名といいね数のデータフレームを(言語ごとに)作る
(1)言語ごとにいいね数の総和を取り、空のリストに追加→df[‘いいね数’].sum() を使う
(2)言語名といいね数のリストから辞書の形でデータフレームを作る - データフレームをいいね数が多い順に並べ替えて出力(print)
df.sort_values(by = ‘いいね数’, ascending=False) を使う
DAY37 <課題解説>Twitterから言語ごとのデータを収集しよう
コードリーディングについて
以下金言だと思いました。
意外とこれは盲点なんですが、慣れていない方はコードを上から順番に読もうとしてしまいます。
大体がめちゃくちゃ読みにくいと思います。
その理由は上に書いてあることはほとんど下で使うための準備だからです。
ですので、「これはなぜimportしてるのか?」とか、「この変数は何に使うのだろう?」とか見ただけでは分からないことが多いと思います。
実は、「コードは(作りたいもの)結論が最後に書いてあることが多いです。」
ですので、最終的に何を作りたいのか?その結論をまず見つけます。
そしてその結論はmain()関数の最後に書いてあることが多いんです。
Pythonコース DAY37 教材より
他人のコードを見て参考にするとき、この考えは特に役立つと思います。
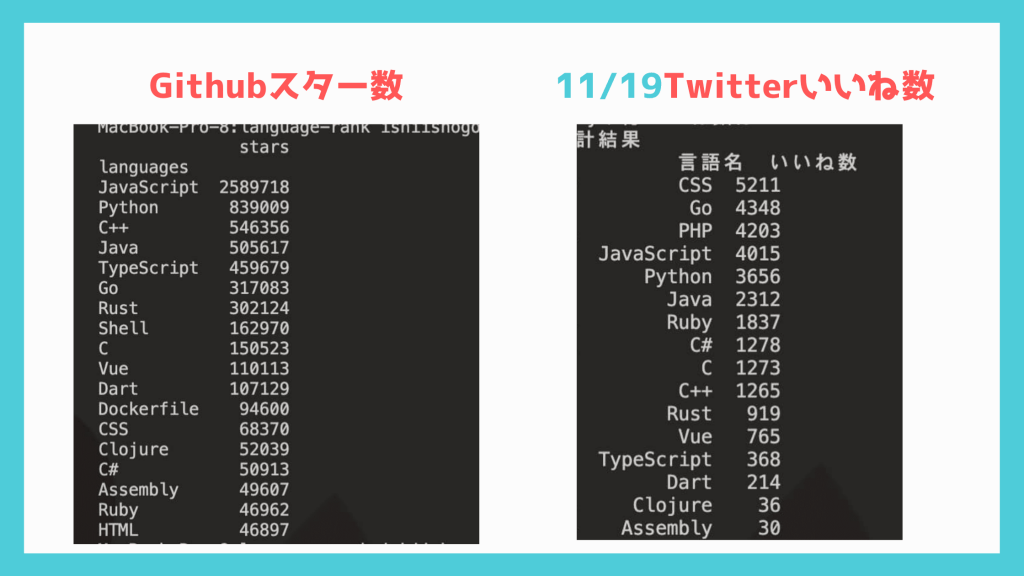
取得できたデータと考察
以下のようなデータが取れました。
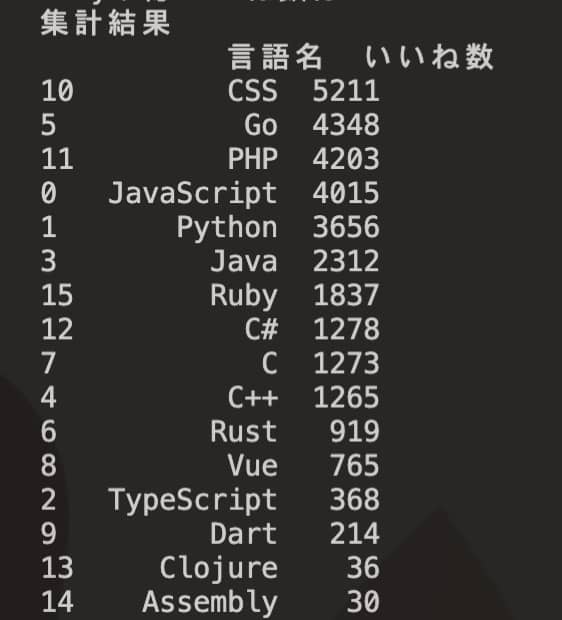
さきほどのGithubとは全然違った結果になっていますね。
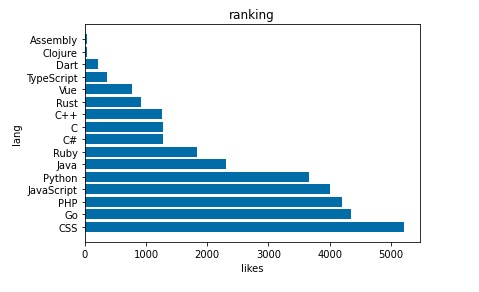
また独自にTwitterいいね数をグラフにしてみました。
特定のキーワードで直近で10万回以上再生されバズっている動画をリストアップしよう
特定のキーワードで直近で10万回以上再生されている動画をリストアップする
- YouTube APIキーを取得する
- YouTube APIの基本的な使い方を学んでいく
- 特定のキーワードでバズっている動画のリストアップ①
- 特定のキーワードでバズっている動画のリストアップ②
- 結果をグーグルスプレッドシートに書き込む

DAY38 YouTube APIを取得しよう
このパートではYouTube APIを取得するのですが、初期状態だと使えるリクエスト数が少ないです。
なので、YouTube APIの上限を増やす(45倍にする)ために申請するところまでやっていきます。
YouTube API上限申請方法
多くの人がここで苦戦するかと思いますので、私の公式とのやり取りを残しておきます。
申請フォーム送信後の返信
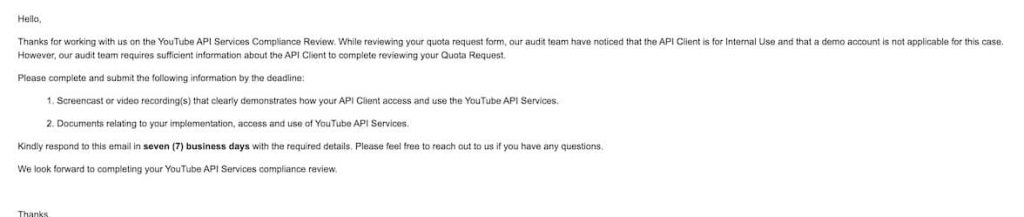
- どうあなたのサービスがYouTube API使うか動画で見せろ
- サービス仕様のドキュメント用紙しろ

動画とドキュメントを添付しましたが、自分で用意するのが難しくデイトラに載っていたpdfと、動画はデイトラのアプリ動作動画のスクショでそのまま送ってしまいました(作るのは同じアプリなので問題ないはず…というよりそれ以外の手段がない)

- スクリーンキャストで取得されてるデータがYouTube APIからのか確認させて
- 集めたデータで何するか教えて?
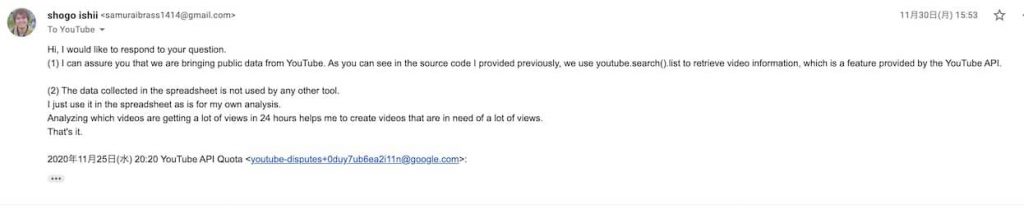
- YouTube APIからのデータですよ、youtube.search.listってメソッド使ってるでしょう?
- データ集めて見て分析するだけです。スプシに入れて終わりです。

そして14日後

上限申請認めるよ
DAY39 Youtube APIの基本的な使い方を見ていこう
DAY40 特定のキーワードで10万回以上バズっている動画をリストアップしよう①
DAY41 特定のキーワードで10万回以上バズっている動画をリストアップしよう②
ここまではAPI経由で取得して得られたデータをDataFrameにして整形していきます。

DAY42 結果をグーグルスプレッドシートに書き込みしよう
実行して得られた情報(DataFrame)をグーグルスプレッドシートに書き込むプログラムを作成していきます。
書き込む処理はこれまでも使用した「gspreadモジュール」を使用していきます。

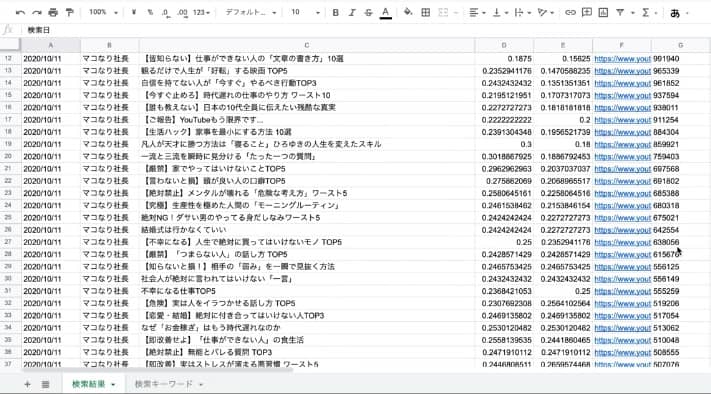
その後、「フリーランス」のキーワードで検索をかけた結果、50件近くヒットしました。動画のトピックも様々で、多用な攻め方が見えますね。

\業界最安のPythonスクール/
形態素解析を使ってバズってる動画によく使われている決め台詞(ネガポジ分析)
今まで作成したプログラムを参考にバズったYoutubeのタイトルのネガポジ分析をしていきます!
これによって、バズる動画タイトルにはどのような傾向があるのかを分析することができます。
レッスン内容
DAY43 バズった動画のタイトルを形態素解析して入っているキーワードの割合を調べる
DAY44 バズった動画のタイトルをネガポジ分析してプラスかマイナスかどちらがバズり安いか調べてみよう①
DAY45 バズった動画のタイトルをネガポジ分析してポジかネガかどちらがバズり安いか調べてみよう②
今回は
- プログラミングという単語で
- 一年で10万回再生されている動画
を検索対象に、ネガポジ分析を行いました。

基本的にポジティブ度が多いですね。
特定のキーワードで24時間以内に数万回再生されている動画が出たらLINEに通知しよう
特定のキーワードで24時間以内に数万回再生されている動画のLINE通知をしてくれるプログラムを作成していきます
DAY46 LINE Notifyの設定をしよう
DAY47 バズった動画を調べて通知できるようにしてみよう
DAY48 herokuを使って定期実行できるようにしよう
作ったもの
「フリーランス」というキーワードで一週間で1000以上再生された動画を毎日通知してくれます。
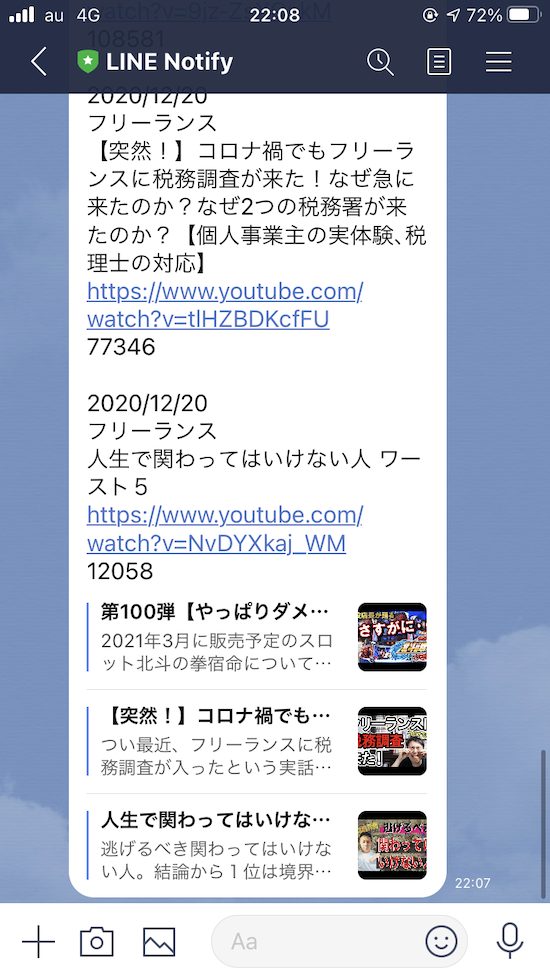
これによって、今どんな動画が流れ着てるのか判断し、動画投稿することができます。
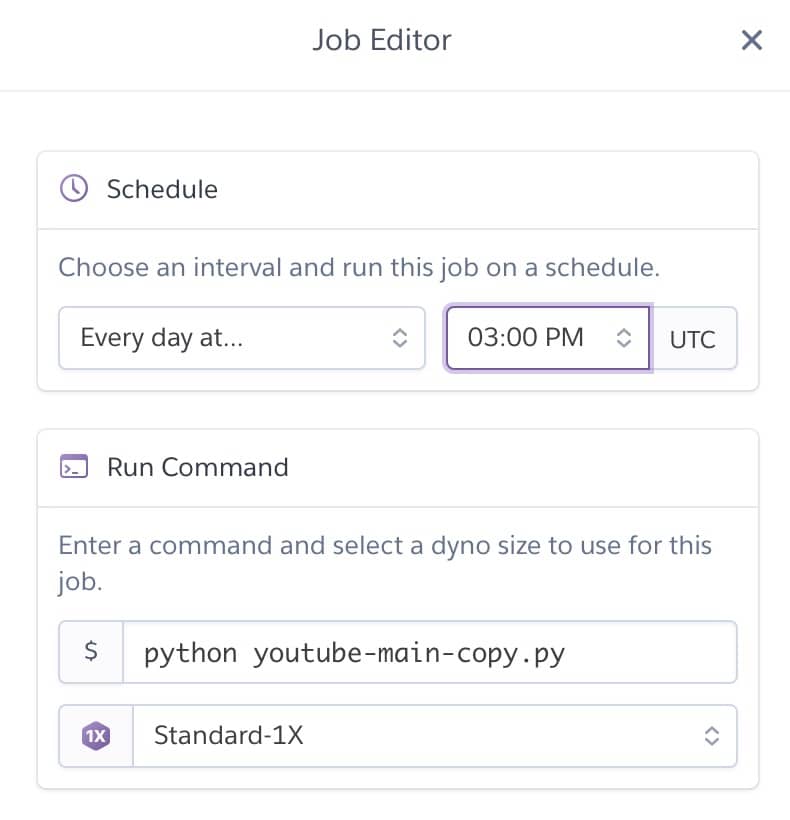
MacBookProの場合はBetter Touch Toolでプログラムを定期実行できるので、自分のPCでも定期実行することができます。


自分の動画がライバルの関連動画にどれぐらい露出され順位はどのくらいか調べよう
自分の動画がどんなライバルの関連動画に表示されいているのか?をリアルタイムでデータとして取得できるコードを作成
関連動画とは?
下記の位置の動画のことです。
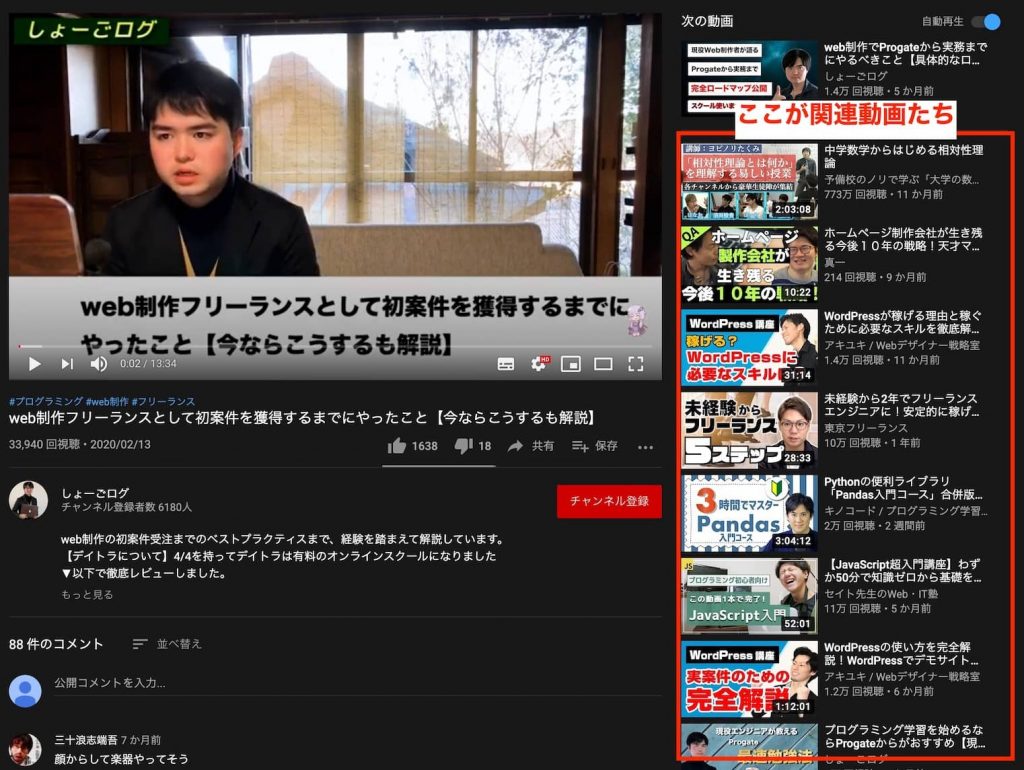
私たちのような「YouTube動画投稿者」たちは、自分の動画はライバルチャンネルにどれぐらい関連動画として露出しているのかを知る術がありません。
- いつ関連動画に載ることができたのか?
- 今は誰の関連動画に載っているのか?
- 相手のチャンネル名は?動画タイトルは?
- 再生回数はどれだけなのか?
YouTube Analyticsでは見れないのです。
しかし自分のチャンネルを伸ばすには大変有用な情報になります。
これらの情報で流入元の動画を見ている視聴者に合わせて自分の動画を最適化していくことが可能になります。
どんな話題を動画で話すべきなのか?、サムネイル、タイトルに入れるキーワードは?動画の長さはどれぐらいなのか?
などを流入元の動画を見て調査して、それに合わせて対策していくことが可能になります。
つまり今回のプログラムを書くことができれば
YouTuberは自分のビジネスに役立つし
プログラマーとして動画投稿者にツールを販売することもできる
というわけなのです。

- YouTube APIでライバルの更新動画を収集する
- YouTube APIでライバルの動画の関連動画を収集する
- 関連動画の中に自チャンネルの動画があるかを調べ、もしあれば関連動画ないの順位と動画情報を収集する
DAY49 自分の関連動画のタイトルを抽出してみよう
DAY50 ライバルの動画の関連動画を抽出してみよう①
DAY51 ライバルの動画の関連情報を取得してみよう②
機械学習を使って世界規模の株価予測コンペで賞金をゲットしよう
DAY52 Numeraiについて学ぼう
DAY53 Numeraiに登録しよう
DAY54 機械学習手法について学ぼう
DAY55 トレーニングデータとトーナメントデータを読み込もう
DAY56 Numeraiに予測を提出しよう
\業界最安のPythonスクール/
ここまで読んでくれたあなたへ

こんな長い記事の最後まで丁寧に読んでいただき、本当にありがとうございます!
ここまでスクロールしてくれるユーザーは10%未満の方しかおらず、大変うれしく思っております!
実は、この記事のリンクはすべて「アフィリエイトリンク」になっています。
この記事から商品を購入していただけると、いくらか私にキックバックがあるというものです。

まあこの記事の内容が参考になったから、申込みはこの記事からしてあげるよ
そう思っていただけたら、この記事のリンクからお申し込みいただけたら、とてもうれしく思います。
このブログは「それが知りたかった!」をモットーに運営しており、今後の活動のモチベーションに繋がります。
\ここまでありがとうございます!/
デイトラ申し込みから学習開始までの流れ
まずはデイトラ![]() で申込みを行います。
で申込みを行います。
その後、受講したいコースを選択します。

その後「クレカ支払い」か「銀行振込払い」か選択します。

銀行振込まで対応しているオンラインスクールはほとんどないので、助かりますね!


支払い後は「申し込み完了メール」が来るので、Slackに参加できるのと、講座も受講できるようになります。
\無料動画が複数あり!/
- YouTube分析アプリ、株価予測アプリなどを実際に開発
- 実務で使いたいアプリについてプロに相談可能
- カリキュラムはずっと見放題、講師へ一年間質問可能
- 数学不要でも取り組めるカリキュラム
- カリキュラム以外の開発に関する質問もOK!
\Pythonを本気で仕事にしたいあなたへ/
| コース名 | Web制作コース | Web制作アドバンスコース | Webアプリ開発コース | Webデザインコース | ShopifyEC構築コース | 動画編集コース | Webマーケティングコース |
| 学習内容 | Webサイトの構築 | Web制作の一歩上の フロントエンド技術 | Rails,Reactでアプリ開発 | Webやアプリデザイン | Shopifyサイトの構築と 運用 | YouTubeや ショート動画編集 | 広告やSEO LINEやレポーティング |
| 料金 | ¥129,800 | ¥79,800 | ¥129,800 | ¥129,800 | ¥99,800 | ¥99,800 | ¥109,800 |
| 卒業後の進路例 | Web制作会社に就職 フリーランスコーダー | コーダーからキャリアアップ フロントエンドエンジニア | Railsエンジニアとして 企業に就職 | フリーランスデザイナー デザイン会社に就職 | EC構築フリーランス Shopifyエキスパートの会社に就職 | YouTube,TikTokeの編集者 企業の動画広報担当 映像編集会社へ就職 | フリーランスで広告運用 マーケターとして就職 |
| 解説記事リンク | Web制作コースの評判・内容 | Web制作アドバンスコースの評判・内容 | Webアプリ開発コースの評判・内容 | Webデザインコースの評判・内容 | Shopifyコースの評判・内容 | 動画編集コースの評判・内容 | Webマーケコースの評判・内容 |
| 公式サイト | Web制作コース | Web制作アドバンスコース | Webアプリ開発コース | Webデザインコース | ShopifyEC構築コース | Webマーケティングコース |
HTML初心者からWordPress実案件レベルまでのコーディング演習課題を「専用ページ」にて公開しています。2026年も案件獲得や転職に成功した人が多数出ています。

- Figma,Photoshopデザインからのコーディング
- サーバーアップロードでサイト公開
- プロによる最大3回の表示確認特典
- レビュー返しは爆速
- 2024年にデザイン刷新!被らないポートフォリオ
「初級編」は初めてデザインからコーディングする方向け
「中級編」はJavaScriptやjQueryの練習
「上級編」はWordPressの実案件を模擬体験できるレベル感にしています。
中級者の方には高難易度課題を詰め合わせた「即戦力セット」も出しています。
全課題で「実務レベルの、プロの厳しいレビュー」を受けられるようにしています。
また、2025年には随時デザインの刷新をしており、完全リニューアル!!
他者と差をつけられるポートフォリオが準備できます!

制作会社も使用する専用レビューツールで分かりやすく添削していきます!
基本的に「まとめて購入」していただくとかなりお得になります↓

コーディングは書籍だけではなかなか実力がつかないので、実務レベルのレビューを受けて自身をつけたい人は是非挑戦してみてください!

\課題の購入はこちらから/
しょーごログのコーディング課題後に、ニートから最大月収100万を稼げる用になった方のインタビュー記事も参考になるはずです。


















余談ですが、デイトラが全体的に良心的な価格で講座を提供できているのは、広告費をかけずともTwitterやYouTubeなど無料のSNSで集客できているからだそうです。